Введение
Эта статья выходит как продолжение статьи Какой должна быть капча?
Здесь мы рассмотрим существующие решения различных защит CAPTCHA их минусы и плюсы, стойкость к распознаванию и читаймость со стороны человека.
Естественно вы должны давать себе отчет в том для чего вы разрабатываете защиту от спам ботов на своем сайте. То есть конкретно от чего вы хотите защитится? Вариантов два:
1) От случайных спам-ботов. Существует много спам-ботов, гуляющих по интернету, и пытающихся заспамить любые формы. Если форма защищена капчей, он пытается ее распознать автоматически. Если капча очень простая, ему это получается, если капча хотя бы чуть-чуть усложнена то у него не получается распознать и бот идет искать другую форму.
2) От целенаправленного взлома капчи. Это когда кто то садится писать программу-анализатор целенаправленно под вашу защиту, учитывая все особенности генерации вашей капчи.
Защищаясь от случайных спам ботов достаточно будет реализовать какую нибудь простенькую защиту на JS без картинки. Или если вы таки решились на CAPTCHA то достаточно будет очень простой капчи.
А вот от целенаправленного взлома вас не спасет ни один алгоритм. Тут скорее вопрос в том сколько ресурсов готов потратить взломщик на вашу защиту. Если ему понадобится для этого нанять десяток программистов, а также арендовать пару десятков серверов, то я думаю он откажется от этой затеи.
Алгоритмы
Возьмем самую простейшую капчу и попытаемся ее усложнить . Вот такой рисунок у нас будет подопытным

1. Случайный шум
Очень часто разработчики накладывают шум на картинку. Вот например вот так:

 Но они видимо не знают, или не догадываются что такой шум очень легко убрать. Смотрите сами. Весь шум состоит из множества случайных пикселей. Попробуем взломать капчу с шумом. Чтобы убрать шум, анализируем каждый пиксель на картинке.
Но они видимо не знают, или не догадываются что такой шум очень легко убрать. Смотрите сами. Весь шум состоит из множества случайных пикселей. Попробуем взломать капчу с шумом. Чтобы убрать шум, анализируем каждый пиксель на картинке.
![]()
А точнее анализируем пиксели вокруг него. Если количество закрашенных пикслей вокруг него меньше определенной константы, то этот пиксель является шумом, если больше то этот пиксель принадлежит картинкe. Убираем пиксели определенные как шум и получаем чистую картинку. В зависимости от силы шума проходим алгоритм несколько раз. Посмотрим что получится у нас:

 Ой) В первом случае мы получили практически оригинальную картинку. А во-втором случае мы получили картинку с парой клякс и чуть-чуть кривыми цифрами, но ни то ни другое не скажется на качестве распознавания.
Ой) В первом случае мы получили практически оригинальную картинку. А во-втором случае мы получили картинку с парой клякс и чуть-чуть кривыми цифрами, но ни то ни другое не скажется на качестве распознавания.
Итого имеем усложнение читамости, практической пользы — нет.
2. Случайные линии

 Хм, а давайте проведем эксперимент? Применим к обоим картинкам предыдущий фильтр «антишум», в несколько раундов и получим…
Хм, а давайте проведем эксперимент? Применим к обоим картинкам предыдущий фильтр «антишум», в несколько раундов и получим…

 Ну вот и линий не осталось. Конечно вторая картинка пострадала немножко, но не настолько чтобы ее нельзя было распознать.
Ну вот и линий не осталось. Конечно вторая картинка пострадала немножко, но не настолько чтобы ее нельзя было распознать.
Итог: Смысла в линиях нет
3. Сетка
Еще один из примеров это наложение сетки:

Не знаю на что рассчитывают авторы, но это вообще глупость какаято. Опять применяем банальный антишум и получаем:

Конечно не обязательно использовать «антишум». Можно програмно высчитывать шаг сетки и убирать ее. Но обычно все сетки делают толщиной в один пиксель, и «антишума» будет достаточно чтобы ее убрать.
То есть толку от наложения сетки нет..
4. Игра цветами
Тут конечно очень много вариаций как можно сгенерировать картинку.
 Допустим сделать разноцветный шрифт. Смысла нет. Определяем цвет фона, и все отличное от цвета фона закрашиваем в черный цвет. Так получаем оригинал. Цвет фона кстати определить очень просто, достаточно высчитать наиболее встречаемый цвет — он и будет являтся фоновым.
Допустим сделать разноцветный шрифт. Смысла нет. Определяем цвет фона, и все отличное от цвета фона закрашиваем в черный цвет. Так получаем оригинал. Цвет фона кстати определить очень просто, достаточно высчитать наиболее встречаемый цвет — он и будет являтся фоновым.
 Сделать разноцветный фон и оставить шрифт черным. Опять не правильно. Заменяем все «не черные» пиксели (т.е. цветной фон) на белые и получаем полностью оригинальную капчу, которая в дальнейшем с легкостью распознается.
Сделать разноцветный фон и оставить шрифт черным. Опять не правильно. Заменяем все «не черные» пиксели (т.е. цветной фон) на белые и получаем полностью оригинальную капчу, которая в дальнейшем с легкостью распознается.
 Разноцветный фон и разноцветный шрифт. Вот эта капча немного будет более стойка к расшифровке. Но при этом, очень сложно написать такой алгоритм, чтобы цвет нужных букв не совпадал с цветом фона в этом месте, иначе человек не сможет понять что там написанно.
Разноцветный фон и разноцветный шрифт. Вот эта капча немного будет более стойка к расшифровке. Но при этом, очень сложно написать такой алгоритм, чтобы цвет нужных букв не совпадал с цветом фона в этом месте, иначе человек не сможет понять что там написанно.
Итог: при правильном подходе, можно увеличить стойкость капчи. Но необходимо обязательно учитывать тот момент чтобы пользователь смог эту капчу потом прочитать.
5. Уменьшение контраста с фоном

Для машины отличие даже в один бит — это уже абсолютно разные цвета. И машина сможет распознать даже такое изображение:

Бьюсь об заклады вы подумали мол «что за серый прямоугольник», но вглядитесь, там видны контуры цифр, (или у вас хреновый монитор).
Итог: бесполезно
6. Градиентные цвета
Такой алгоритм генерации считается стойким к програмному распознанию, так как почему то считается что «не существует алгоритма позволяющего выделить участок с текстом из картинки». Давайте развеем этот миф и взломаем градиентную капчу. Возьмем вот такой градиент:

Пусть все цвета для градиента выбираются случайно и так чтобы всегда был контраст с фоном (во всех подобных капчах так и происходит).
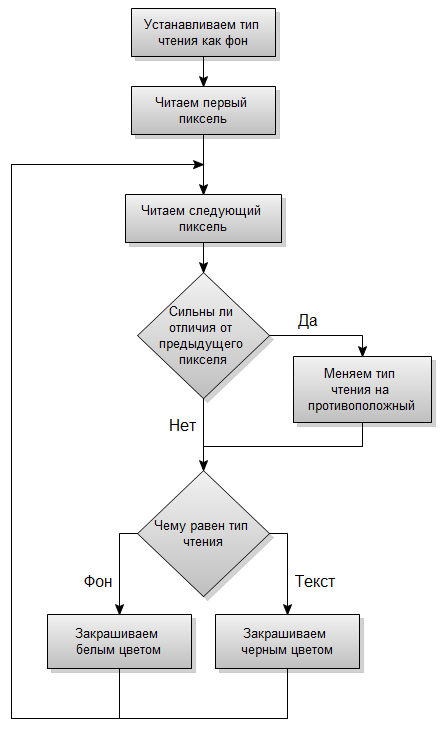
В данном случае всякие увеличения/уменьшения контрастности/яркости не помогут выделить текст. И тут многие программисты становятся в тупик. Но делается это элементарно. Выделим часть строки пикселей из этой картинки:

Обратите внимание. В градиенте соседние пиксели лишь незначительно меняют свой цвет. Резкий контраст происходит на границах с цветом текста. На основе этого факта пишем программу, которая будет построчно обходить картинку (алгоритм для каждой строки в виде блок схемы).
И после того как наша программа пройдет по всей картинке мы получим полностью оригинальное черно-белое изображение, распознать которое не составит труда.
Что имем в итоге? Затраты на генерацию такой картинки в разы выше чем у обычной картинки, т.к. закрашивание градиентом — ресурсоемкая задача. Но при этом эта защита обходится относительно просто. Вообщем опять толку нету.
7. Смещения символов

Весь алгоритм сводится к поиску «самых темных» участков с размерами приблизительно соответствующим размерам символов. Выделяем такие участки и распознаем. Как выделять области с символами из изображения смотрите ниже.

Фактически опять ничего не изменилось. Нет никакого увеличения стойкости.
8. Вращение символов
Еще один используемый метод это вращения/наклоны символов. Вот пример этого:

Идея распознавания очень проста. Мы вырезаем отдельный символ и вращаем его до тех пор пока ширина квадрата в который вписывается символ не станет минимальной. Возьмем тройку из этой капчи в качестве примера и попробуем повращать влево и вправо:

(Под каждым символом указанна ширина в пикселях)
Как видите — теория верна. Мы нашли оригинальный символ. Тоже самое повторяем для остальных символов и получаем в итоге оригинальную картинку.
И снова капча взломана.
9. «Склеивание» символов
Ну и конечно многие считают что «склеивание» символов поможет от разбиения картинки на участки с символами с последующим их распознаванием.

Но и здесь картинку можно элементарно разбить на символы. Кстати именно этот метод позволяет находить положения символов в пункте «6. Смещение символов». Я упущу тот момент что все символы могут быть одинаковыми по ширине и тогда можно будет картинку поделить на равные части. Так вот вырежем участок с символами и увеличим его:

А теперь построим график количества черных пикслей для каждого «столбца пикселей» в изображении:

Согласитесть сразу бросается в глаза три точки минимума соответствующие границам символов. Благодаря этому графику разбиваем рисунок на части и распознаем как обычно. Причем даже если символы частично наложить друг на друга (в разумных пределах), на графике все также будут видны точки минимумов, хоть и не так явно. Что дает возможность распознавать изображения даже с наложениями символов.
Итог: бесполезно
10. Скручивание символов
Рассмотрим скручивание и прочие изменения геометрии символов.

На мой взгляд одна из немногих методик, действительно снижающих процент распознания капчи. Конечно при условии что каждый раз изменение геометрии уникально, иначе можно подобрать параметры обратного преобразования.
Минусы:
— Сложно в реализации
— Ресурсоемко
— Снижает читабельность
Плюсы:
— Сложно для программного распознования
Но опять же, сложно это не значит не возможно. Для решения данной проблемы существует класс алгоритмов называемых «нейронные сети» — им скармливается огромное колличество уже распознанных изображений, алгоритм самообучается на основе этих результатов, до тех пока сам не сможет распознавать новые изображения.
То есть взломщику прийдется длительное время кропеть, распознавая вручную картинки с вашей капчи и скармливая их алгоритму. А это значит что универсальности во взломе таких капчей быть не может. Но если взломщик задастся целью взломать вашу капчу, то рано или поздно он это сделает.
Итог: хоть порой сильно снижает читабельность, но этот метод оправдан
Заключение
При разработке своей CAPTCHA-защиты сайта учитывайте приведенный выше материал, и не пользуйтесь теми методами которые не увеличивают стойкость капчи, так как эти методы в большинстве снижают читабельность кода на картинке (см. золотое правило)



{kind=link}
А что можете сказать насчет такой капчи http://www.dracon.biz/captcha.php
Кто то уже у меня спрашивал про эту капчу… А что именно вы хотите услышать? Любую капчу можно обойти — вопрос в ресурсах.
Эта капча на флеше, и она выводит на экран символы на стороне клиента. А это уже значит, что повторить алгоритм расшифровки не составит труда.
AES например ;-)
Второй вариант: перехватить системные функции печати символа.
Я кстати позже изучал ее, но она сильно обфусцирована, и понять что к чему там практически нереально.
Есть еще и платная версия с открытыми исходниками, но меня жаба задавила покупать просто так.
Там в исходниках скрывают, что это AES-192 ECB ?
Гм… Не помню, если чесно =(
Никак не могу понять как вводить капчу на этом сайте _www.saloed.net используются цветные шарики что делать хз.
Чето ваш коммент похож на рекламу этого сайта…
Автору статьи большое спасибо, вроде все очевидно и элементарно, но уже не раз возвращался к этой статье.
Огромное спасибо за Ваши статьи! почему раньше не попадал на Ваш сайт, пока гуглил что-то по капче?..
Однако есть замечания. Насчёт вращения, думаю Вы недооценили сложность распознавания.
Да, но надо сказать, что многое зависит от шага угла вращения, чем медленнее вращать тем больше этих операций вращения надо предпринять. При этом после каждой надо просчитывать ширину квадрата, что тоже сравнительно ресурсоёмкая задача по 2-м вложенным циклам.
Дальше тоже недооценка по склеиванию:
А если склеены символы 0 и 8, 9-0, и т.п? У них на месте минимума как раз окажется максимум! Единица вообще может прилепиться к нолю настолько, что её почти невозможно будет отделить.
Ну и ещё 2 вопроса к автору, буду благодарен если поможете)
1. Какие эффективные приёмы можете посоветовать для капчи, когда символ не залит цветом, а имеет только контуры а всередине цвет фона? Кстати если символы такие, то добавление линий на капчу уже не обойдёт предложенный Вами метод удаления шума, ведь толщина линий шума и линий символа практически не отличается.
2. Вы упомянули о нейронных сетях. Хотел спросить, как сформировать простое и эффективное пространство признаков символа, для подачи на вход нейронной сети? Что именно туда должно входить? Ведь каждый пискель — это очень затратно по обучению и по затратам памяти на сеть, да и не устойчиво к наклонам, шрифту, толщине..
Ну никто не говорит использовать бездумно обычное вращение. Так например можно использовать бинарный поиск с заданной точностью, что даст с 3-4 итераций приемлемый результат.
Посмотрите еще мои статьи, не помню точно в какой, но в одной из них я предлагал поиск граней методом анализа верхней и нижней границы текста. Но этот метод работает только для символов с круглыми гранями.
Как я уже отвечал на Ваш другой комментарий, каждая капча уникальна. Каких то конкретных советов я дать не могу. Я всегда, перед реализацией алгоритма, садился и думал «как можно взломать эту капчу», проверял поступающие идеи, тестировал, отсеивал, и снова думал. Как правило в процессе находил слабые стороны конкретной реализации которые и выливались в рабочий алгоритм.
Честно сказать, я сильно не заморачивался, подавал на вход простую битовую маску фрагмента с символом. Но да, это не сильно «устойчиво к наклонам, шрифту, толщине», поэтому перед этим я старался проводить предобработку и приводить фрагменты к одному виду. Но на этом мои эксперименты с нейронными сетями, как правило, заканчивались.
Да, да. Вот эта статья.
И всё же, хотелось бы услышать Ваше мнение, как опытного в этом деле. К такой капче как бы Вы подошли? http://imgur.com/W1gwwDo
Хотя бы первые базовые шаги. ЦВет почти всегда одинаков, а фон может кардинально меняться. И могут быть буквы верхнего регистра A-F.
Ещё раз спасибо.
Ну раз цвет всегда одинаков, то выделить сами буквы труда составить недолжно. Да и даже если он каждый раз разный, то т.к. фон заливается градиентом, то цвет букв будет самый используемый, что позволит эти буквы выделить.
Далее я бы наверное эксперементировал бы с анализом пустых областей. То есть для каждой точки определям в какую область она входит — в большую «фоновую» или же в одну их маленьких, ограниченных границами символов. Цель — получить в идеале четыре составляющих этот рисунок области: фоновая, и три символа. Фоновую отбрасываем, символьные распознаем, дело в шляпе. Одна из возможных проблем — внутренние области для символов типа: «6, 8, 9, 0», но я думаю это решаемо
Но не стоит меня воспринимать в серьез) Постарайтесь сообразить что нибудь самостоятельно. Тем более, что перечитав свой коммент, я понял что написал уж слишком непонятно(
Какие эффективные приёмы можете посоветовать для капчи, когда символ не залит цветом, а имеет только контуры а всередине цвет фона?
Сложно сказать. Боюсь что вот так сходу ничего не посоветую, смотреть надо.
А если на капче присутствуют кривые линии с толщиной в стенку буквы? Есть алгоритм для обхождения такой капчи?)
Да фиг его знает, не существует точного набора алгоритмов для распознавания какой бы то ни было капчи. Каждый случай нужно изучать отдельно.
Я про капчу вк, можете что нибудь посоветовать?)) Вся работа на этом встала.. уже неделю мучаюсь…
Чесно сказать даже не помню как эта капча вообще выглядит. Почему бы не подключить какой нибудь сервис по распознаванию капч?
8. Вращение символов
я бы не назвал этот метод легким, скорее средним
сложным — из за трудности реализации алгоритма в языках близким к скриптовым, и легким в реализации на языках питон и си*подобных — с доступными функциями