![]() Краткое отсутпление: статья содержит теоретическое описание алгоритма взлома данной капчи. К сожалению, предложенный алгоритм так и не был реализован на практике…
Краткое отсутпление: статья содержит теоретическое описание алгоритма взлома данной капчи. К сожалению, предложенный алгоритм так и не был реализован на практике…
Когда то давным-давно (наверное полгода-год назад) я обещал опубликовать эту статью. И вот наконец — свершилось! Я ее публикую :)
В данной статье, как я говорил выше, вы не найдете практической реализации данного алгоритма. Но публикую я ее с целью, что некоторые из предложенных идей может быть кому-нибудь, когда-нибудь помогут. Почему так подробно? Потому что когда то я взялся за задачу предложить описание алгоритма распознавания оной. Алгоритм был передан заказчику, но с реализацией чего то не сложилось… Хотя ладно, хватит отступлений.
Так kcaptcha — довольно известная реализация капчи на PHP, гуглится на первой странице по запросу «капча», и выглядит следующим образом:
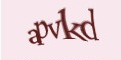
Является довольно сложной капчей, так как используются сильные искажения, и, дай бог памяти, по-моему разные шрифты (не помню уже точно). К сожалению, капча не содержит каких-либо видимых уязвимостей.
Статью я предлагаю вам в том виде, которая отдавалась заказчику, поэтому возможно вас удивит немного другой стиль изложения. По поводу морально-этических норм — все в порядке, не переживайте, прошло уже более двух лет, это было обговорено.
Содержание
Введение
1) Приведение к черно белому виду
2) Выделение фрагмента с кодом
3) Предварительная обработка
4) Разбиение картинки на фрагменты
5) Поиск ключевых узлов
6) Сравнение с базой масок
Заключение
Итак, поехали… (далее очень много букаф и картинок)
Введение
Данной алгоритм разработан мной, и на практике, за исключением части разбиения символов, не тестировался. Но он вполне реализуем и при грамотной реализации он должен работать успешно.
Весь алгоритм состоит из следующих шагов:
- Приведение картинки к черно белому виду
- Выделение фрагмента с кодом из всей картинки
- Предварительная обработка
- Разбиение картинки на отдельные фрагменты с отдельными цифрами
- Поиск «ключевых» точек (узлов) на каждом фрагменте
- Сопоставление масок ключевых узлов с имеющимися в базе
Особое внимание в процессе необходимо уделить разбиению картинки на отдельные фрагменты. Именно от этого шага полностью зависит дальнейший процесс распознавания. Так как мой алгоритм распознавания основан на поиске узлов, то любая лишняя часть другой цифры, ровно, как и по-ошибке обрезанная часть текущей цифры, будет приводить к гарантированным ошибкам распознавания.
Прошу обратить внимание на тот факт что я не смогу описать весь алгоритм полностью, поэтому конечному программисту придется проявить немного творчества. Конечно, я распишу все максимально подробно (в некоторых местах может быть и получилось через-чур очевидно, но для разных людей эти вещи могут быть очевидны, а для некоторых нет), но все-таки реализация данного алгоритма останется за конечным программистом.
В качестве примера возьмем следующую капчу:

(Здесь и далее картинка увеличена в два раза для наглядности)
1) Приведение к черно белому виду
Здесь все просто. Для унификации распознаваемых картинок, можно анализировать цвет фона картинки. Для этого подсчитывается количество использований каждого цвета на всей картинке. Самый используемый цвет будет являться цветом фона. Для нашей капчи этот цвет всегда белый (#FFFFFF).
Все цвета всей картинки, отличные от определенного нами цвета фона, устанавливаем в белый цвет. Все остальные цвета устанавливаем в черный. В итоге должно получиться следующее изображение:
При этом естественно закрашивать стоит с учетом небольшой погрешности, в пару десятков единиц для каждого канала цвета. То есть любой цвет от #FFFFFF до #EBEBEB должен закраситься как фоновой.

В принципе, можно пойти по другому пути, и использовать стандартные фильтры. Устанавливая контрастность в максимум, с помощью изменения яркости добиваться нормального качества изображения, это даст возможность подбора оптимальной толщины линий каждой цифры (чем выше яркость, тем тоньше линии – отсекаются тона, соответственно яркость придется подбирать экспериментально). Но как показывает практика, хватает и обычного метода, описанного выше.
2) Выделение фрагмента с кодом
Также является довольно простым шагом в данном алгоритме. Для определения границ слева и справа

алгоритм должен проходить каждый «столбец» пикселей до первого столбца, в котором будет найден черный пиксель. В идеале первый столбец с как минимум одним черным пикселем будет являться найденной границей.
В реальности предыдущий шаг может оставить какие-либо шумы, что приведет к ошибке определения границы. Для устранения возможных ошибок, можно увеличить порог срабатывания (к примеру, искать минимум три черных пикселя), либо увеличить количество анализируемых столбцов (к примеру, три столбца подряд должны содержать черные пиксели).
Для определения границ сверху и снизу алгоритм должен анализировать уже соответственно строки, в основном принцип тот же.
Для оптимизации и ускорения поиска границы можно использовать двоичный поиск.
Для справки, это поиск, в котором при каждой итерации диапазон делится на два, и, в зависимости от результатов итерации, поиск продолжается либо в левой, либо в правой части диапазона.
К примеру, рассмотрим поиск левой границы картинки. Для начала прикидываем ее возможное «расположение», логично будет предположить, что она может находиться от первого столбца, до столбца посередине (конечно в реальности есть смысл сузить стартовый диапазон, но это всего лишь демонстрации оптимизации):

Анализируем средний столбец в этом диапазоне:
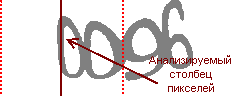
И так как данный столбец уже содержит черные пиксели, значит граница текста находится левее анализируемого столбца:

Следующий шаг сузит диапазон поиска в два раза до такого:

В конце концов, в диапазоне останется только один столбец, и именно он будет являться искомой границей.
В общем, так или иначе, в конце данного шага вы должны получить следующую картинку:

3) Предварительная обработка
Смысл данной обработки заключается в выравнивании написанного кода, то есть в частичном уменьшении искажений. Для этого анализируется верхняя и нижняя полосы изображения, с целью определения растянутости или сжатия по вертикали каждого символа.
Данный шаг можно назвать необязательным, но вполне возможно, что в каких-то ситуациях он увеличит процент правильного распознавания.
Для этого проходим все черные точки, которые расположены как бы «сверху»:

И если представить то, что обведено красным на данном рисунке в виде отдельного графика,
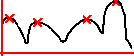
то локальными максимумами данного графика будут являться вершины цифр, т.е. следующие точки:
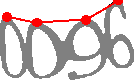
Точно такие же точки мы ищем и снизу картинки:

И в итоге получаем те линии, от которых мы сможем рассчитать степень кривизны по вертикали. Если «растянуть» за эти точки изображение до его границ, мы получим следующее:

(на самом деле получим немного другое изображение с меньшими деформациями чем это, так как данный рисунок я рисовал в графическом редакторе, и нормального растягивания в нем нет, из-за этого получились бОльшие погрешности на девятке и шестерке)
4) Разбиение картинки на фрагменты
Один из самых сложных и ответственных шагов в алгоритме.
В данной капче отсутствует отступы между символами, что очень сильно усложняет задачу. Возможно если бы не данный факт, то само распознавание было бы на порядок проще, но, к сожалению, приходится использовать более сложные алгоритмы разбиения на отдельные фрагменты.
Предлагаемый метод похож на метод из «предварительной обработки», но его суть заключается в поиске не локальных максимумов, а локальных минимумов.
Соответственно локальные минимумы ищем как сверху:

Вот так будет выглядеть график:

Так и снизу:

И соответственно график:
![]()
Крайние минимумы можно откидывать, и если нанести остальные оставшиеся минимумы, то получим точки, соединив которые, мы сможем разделить картинку:

Этот метод будет работать идеально для любых шрифтов, в которых верхняя и нижняя часть символов имеет скругление. Либо на всех остальных шрифтах и надписях, в которых есть хоть какой-нибудь отступ между символами. Хотя конечно такой метод может давать ошибки:

(здесь отрезается лишняя часть нуля и лишняя часть четверки)
Также следует учесть ситуации, когда количество «минимумов» сверху и снизу не совпадает. В таких случаях надо пытаться дорисовывать недостающие точки минимумов по известным точкам с одной из сторон. К сожалению, пример не могу привести, но, я думаю, смысл понятен.
Каждый отдельный фрагмент нам необходимо увеличить до определенного (константного) размера. Именно этого размера будут маски, и именно этот размер будет использоваться дальше.
В исходной капче (kcaptcha), в самый высокий символ – 27 пикселей, а самый широкий – 17 пикселей. Следовательно, изменять размер каждого фрагмента стоит именно до этой ширины и высоты (растягивая или уменьшая исходный фрагмент).
На входе из данного шага у нас должно получиться несколько фрагментов одинакового размера, количество данных фрагментов должно соответствовать количеству цифр оригинального кода.
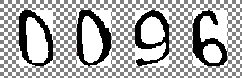
5) Поиск ключевых узлов
Теперь самая сложная и ответственная часть. Этот метод был разработан мной, но на данный момент пока не имеет практической реализации. Все остальные методы: сравнение с маской, нейронные сети – на данной капче работать не будут из-за довольно сильных искажений.
5.1) Теория
Наша задача состоит в написании такого алгоритма, который бы смог определять ключевые узлы на каждом фрагменте с отдельной цифрой. Что я называю «ключевым узлом»? Представим любую точку на картинке, она может:
 — Быть фоновой
— Быть фоновой — Лежать на линии
— Лежать на линии — Быть «концом» линии
— Быть «концом» линии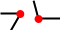 — Быть вершиной угла (острого или тупого)
— Быть вершиной угла (острого или тупого)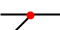 — Лежать на примыкании еще одной линии
— Лежать на примыкании еще одной линии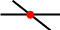 — Быть центром пересечения двух линий
— Быть центром пересечения двух линий
Остальные случаи нас не интересуют, так как все цифры описаны только с помощью этих точек:
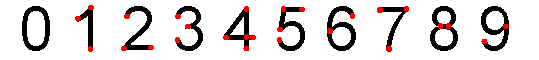
Как видно, каждая цифра имеет свой уникальный «отпечаток», именно этот «отпечаток» (далее маска) будет сравниваться с уже имеющимися масками в базе.
Но, к сожалению, все было бы слишком легко, если бы не было так сложно. На мой взгляд, алгоритмически будет довольно сложно находить узлы с примыканиями, пересечениями и прочее. Конечно, если у вас это получится, то это будет, наверное, лучше чем, то, что я предложу далее. Но, беглый анализ капчи говорит о том, что предлагаемого мной варианта далее, должно хватить.
5.2) Поиск конечных точек
Я предлагаю искать только конечные точки, то есть те точки, которые лежат на концах линии. Это очень просто. Если черный пиксель с одной стороны имеет продолжение (черные точки), а с остальных сторон окружена фоном значит это конечная точка.
Возможно, вы сможете/захотите/посчитаете нужным придумать свой вариант реализации данного поиска. Я же предложу способ простейший, на мой взгляд, основанный на анализе непустых секторов от анализируемой точки. Это хорошо проиллюстрирует данная картинка:
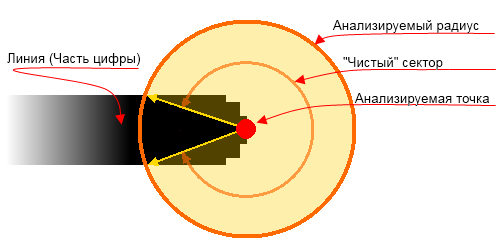
Как вы поняли, мы анализируем все пиксели, лежащие на некоем радиусе (данный радиус надо будет подобрать экспериментально) от каждой точки. Дуга без черных пикселей определяет так называемый «чистый» сектор – сектор, в котором данная точка не имеет продолжения в виде закрашенных пикселей.
Допустим задав минимальную ширину «чистого» сектора приблизительно в 200-270 градусов, данный алгоритм будет находить также и слияния линий под острыми углами что, в общем-то, нам тоже пригодится.
В итоге имеем вот такой вот набор узлов для каждой цифры:
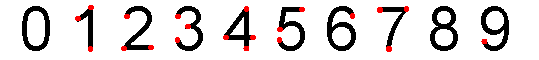
Как видно, все цифры, за исключением нуля и восьмерки имеют свой набор ключевых узлов. Для нуля и восьмерки придется делать отдельный анализ, но это, как мне кажется, не составит труда даже для начинающего программиста.
5.3) Векторизация
Может быть само понятие «векторизация» здесь не уместно, так как здесь используются направленные лучи, а не вектора, но как такового термина «лучезация», насколько мне известно не существует :D
Можно попытаться векторизировать каждый фрагмент изображения.
Векторизировать или нет, я оставляю вам на выбор. С одной стороны это усложнение распознавания, усложнение формата масок и усложнение дальнейшего сравнения с имеющимися наборами масок. С другой стороны это даст возможность трактовать возможные спорные ситуации в пользу той или иной цифры.
Для каждой точки можно определить направление линии, которую эта точка «заканчивает». Началом вектора будет служить сама конечная точка, а направление для него мы сможем узнать, разделив второй сектор пополам, ну в общем как то так:
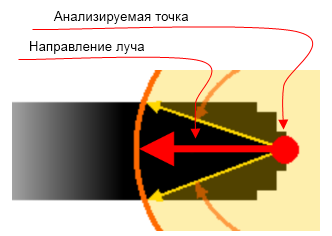
Если прикинуть маски некоторых символов, то это будет выглядеть так:

Но как я говорил выше, это усложняет формат масок. Теперь маска каждого символа будет состоять из описания лучей, а лучи в свою очередь из координат начальной точки и направления луча в градусах от 0 до 359.
5.4) Группировка точек
В капче каждая линия нарисована толщиной больше чем один пиксель. Следовательно, конечных точек будет определяться больше:

Для того чтобы вычислить одну правильную, нам необходимо задать опять же некий радиус, внутри которого все найденные точки будут группироваться в одну. Для группируемых точек вычисляется среднее арифметическое как для координаты, так и для направления (думаю, это не составит большого труда)

И именно эта точка будет использоваться как ключевая точка.
6) Сравнение с базой масок
База масок должна содержать маски для каждой цифры. Возьмем, к примеру, шрифт «calisto» (он больше всего похож на используемый в данной капче) из набора в kcaptcha:
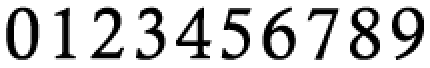
(Приблизительно так должны выглядеть цифры без искажений)
Попробуем представить, как должна выглядеть маска для цифры шесть. Для этого вырезаем, растягиваем и немного огрубляем изображение:

Затем находим ключевые точки:

Такая точка здесь одна. И с этой цифрой все просто.
Попробуем взять единицу. В зависимости от ситуации, выбранного радиуса анализа, ошибок, шумов, искажений и прочих факторов, ключевых узлов в ней может быть от двух до четырех:
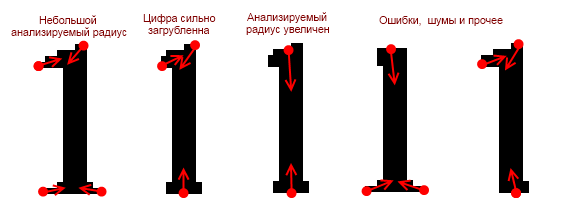
Для того чтобы снизить количество возможных вариантов, надо увеличить анализируемый радиус, подобрать ширину сектора, и поэкспериментировать с радиусом группировки.
В идеале у единицы должно остаться всего лишь две ключевые точки, по одной сверху и снизу соответственно (третий пример на картинке выше). Но, возможно, при таких настройках появятся проблемы с другими символами. Поэтому я бы не советовал ставить большие радиусы, а советовал бы создавать набор нескольких возможных масок для каждой цифры в совокупности с небольшим увеличением радиусов.
Конкретно для единицы я бы создал четыре маски (примеры ищите выше на картинке):
Два узла сверху, два узла снизу
- Два узла сверху, один узел снизу
- Один узел сверху, два узла снизу
- Один узел сверху, один узел снизу
Это бы позволило оставить приемлемые радиусы, было бы достаточно, чтобы описать любые ситуации связанное с этой цифрой, и в итоге повысило бы точность распознавания. Таким же способом я бы подходил бы и к остальным цифрам.
6.1) Сравнение с масками
После того как мы получили или уже имеем полную базу составленных масок для каждого символа, мы, наконец, приступаем непосредственно к самому распознаванию.
Для этого мы находим ключевые точки на всех фрагментах каждой картинки, и, анализируя их или сравнивая с базой масок, мы сможем ответить, какая цифра изображена на конкретном фрагменте.
6.2) Частные случаи при сравнении масок
 Вспомним нашу изначальную капчу. Конкретно на ней, у нас присутствует два частных случая:
Вспомним нашу изначальную капчу. Конкретно на ней, у нас присутствует два частных случая:
- Два фрагмента без ключевых точек. Значит на них изображены либо «ноль», либо «восемь» так как это единственные символы без ключевых узлов. Отличить их просто. Достаточно пройти середину фрагмента сверху вниз и подсчитать количество «черных полос» (переходов белое – черное – белое), если их всего две – значит это ноль, если их три значит это восьмерка.
- Два фрагмента с одной ключевой точкой. Значит это, скорее всего, либо «шесть», либо «девять». Отличить их очень просто. Для шестерки ключевая точка находится выше середины фрагмента, для девятки – наоборот ниже.
Как видите, минимум четыре цифры можно определить однозначно, не прибегая к базе масок, что может дать небольшой прирост в скорости распознавания. Чисто теоретически можно разложить все цифры на частные случаи, и не прибегать к созданию базы масок, но практически это будет довольно сложно.
6.3) Погрешность при сравнении масок
Данный способ сводится к простому ответу на вопрос, соответствует ли конкретной маске полученный набор ключевых узлов или нет.
Так как капча имеет искажения, то, как направление, так и сама точка может быть смещена. Это надо учесть, и добавить диапазон погрешности:
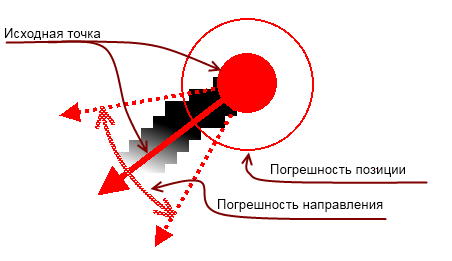
Возможно, погрешность может быть больше (надо подбирать экспериментально). А так как направление может рассчитываться довольно грубо, то задать его погрешность следует где-то в 120-160 градусов (это на мой взгляд, возможно практика подскажет, что это число должно быть меньше).
Таким образом, мы проходим все ключевые точки из каждой маски, и проверяем, есть ли такие же ключевые точки в наборе. Если все ключевые точки найденны и укладываются в погрешность, то это значит, что эта маска соответствует, и мы определили цифру.
Проблема может возникнуть, когда будут заданы слишком большие диапазоны погрешности, так как маски разных символов будут пересекаться. Тогда алгоритм не сможет однозначно сказать, какой из символов верный. Возникнет конфликтная ситуация:
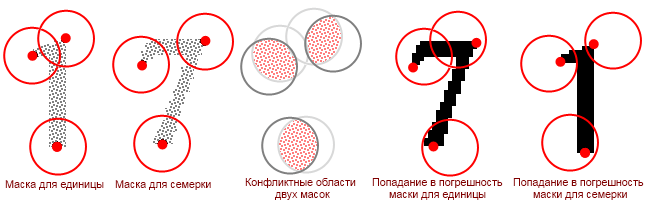
Уменьшение диапазона погрешности будет приводить к снижению процента верных распознаваний. Увеличение – к возникновению конфликтных ситуаций. Избежать этого нам поможет другой подход – расчет степени соответствия.
6.4) Бальная система.
Смысл данной системы заключается в определении степени соответствия между маской и набором узлов на основе штрафных баллов. Подсчет штрафных баллов осуществляется для каждой маски на основе множества факторов:
S=Val1 + Val2 + … + Valn
S – Сумма штрафных баллов
Val1 … Valn – Штрафные баллы за каждый параметр
Каждый параметр мы оцениваем по шкале от 0 до 100 баллов, где 0 соответственно – очень хорошо, а 100 – очень плохо. Попробуем прикинуть какие параметры мы можем оценить:
- Количество узлов в маске и на фрагменте – за каждый не найденный узел мы добавляем по 100 баллов к общей сумме
- Расстояние узла на маске до ближайшего узла на фрагменте – пробуем задать формулой Val=(L / R) * 100, (где L – расстояние между узлом на маске и реальным положением узла на фрагменте, R – допустимый радиус погрешности). То есть чем больше расстояние, тем больший штрафной бал мы начисляем.
- Разница между направлениями лучей узлов – так же задаем формулой:Val=(|Aжелаемый—Aреальный |/ Aпогрешность)*100, (где Aжелаемый – угол заданный в маске, Aреальный – реальный угол на фрагменте, Aпогрешность – допустимый угол погрешности)
Соответственно чем больший штрафной бал получил какой-либо узел, тем дальше он стоит от узла в маске, и тем сильнее он «повернут» в другую сторону.
Все баллы для всех узлов одной маски суммируются. И символ маски с меньшим баллом, будет максимально соответствовать анализируемому фрагменту. Такую же операцию проводим для остальных фрагментов и в итоге получаем распознанную капчу.
Заключение
Надеюсь на то, что мои теоретические рассуждения и предложения окажутся верными и данный материал вам поможет в реализации программы успешно распознающей данную капчу.
Спасибо за внимание!




Большое спасибо! Подобных статей практически нет, а практическая реализация, при желании, не заставит себя ждать когда есть подробно расписанный алгоритм :) В закладки :)
Антон, если решитесь реализовать, отпишите потом о результатах :)
Вполне будут. Уже после 4-го шага у нас получаются достаточно адекватные картинки, после их скелетизации(Тот же алгритм зонга-суня, или что-то получше) вполне можно скармливать их нейронной сети или сравнивать с набором масок, т.к. искажения будут уже не такими уж и большими.
пс. хотя, твоя идея мне понравилось, должно выйти достаточно универсально :)
Да, бесспорно будут. Эта статья писалась заказчику, а мне лично заморачиваться с нейроными сетями категорически не хотелось, пришлось чуть-чуть соврать) Да и вобщем то задача стояла в максимально высокой производительности, нейронные сети все же под этот критерий не попадают. Когда набирал эту статью в блог — думал исправить или нет… решил оставить так, надеюсь вы мне это простите)
у меня сейчас получилось распознать google recaptcha :)
правда при помощи photshop и выравнивания символов в одну линию + fine reader :))
но по факту можно её програмно решать, только не видел реализаций
кстати для fine reader прокатило просто выровнять в одну линию без прокручивания
Огромный труд проделан, уважаю. Хотя и не смогу этого использовать.
Спасибо вам за отзыв. Ну хоть никакой практической пользы вам это, как вы говорите, и не принесло, но надеюсь вам было хотя бы было интересно почитать)
Идея, на мой взгляд, превосходная, которая утвержает факт: «Изобретать велосипеды — стоит!»
По поводу статьи…
Во-первых, можно использовать механизм обучения, в котором, (как в очередь), складываются «маски» распознавания. И в результатирующем выводе — отдавать наиболее вероятностное значение.
Во-вторых, направление векторов, также можно «округлить» в виде «север, запад, юг, восток, юго-восток» и тп. Либо, также, использовать «очередь» определения направления.
В-третьих, ко-всему прочему, можно ещё и добавить коэффициент расстояний между ключевыми точками определённое по линии черчения символа. Например, для «единицы», коэффициент между верхними ключевыми точками много меньше
В-четвёртых, на мой скромный взгляд, бальная система только запутает распознавание…
А в целом и общем, алгоритм, в некоторой степени, применим также и для распознавания рукописного ввода.
PS. «Например, для «единицы», коэффициент между верхними ключевыми точками много меньше»
— чем для цифры «семь».
Да, конечно, в статье изложены лишь общие идеи, и их еще дорабатывать и дорабатывать.
Если чесно, то с этой капчей у меня возникла проблема на этапе разбиения на отдельные символы. На бумаге оно все красиво выглядит, а вот в плане реализации оказалось что успешно разбить таким способом можно не более 30% капч. Если сюда еще приложить погрешность успешного распознавания то получается слишком малый процент успешного пробива (
Ваши статьи с крэк теорией просто супер! Ждём от вас как можно больше новых статей. С такими мозгами в прямая дорога в Оксфорд=)
В общем умоляем вас писать больше. Зарание спасибо!
Спасибо за теплые слова, очень приятно)