 Надеюсь вы помните, я обещал в прошлой статье «Хранение паролей пользователей» предложить вариант того как можно гарантированно избавится от коллизий.
Надеюсь вы помните, я обещал в прошлой статье «Хранение паролей пользователей» предложить вариант того как можно гарантированно избавится от коллизий.
На самом деле, избавится от коллизий в хеш функциях невозможно по одной простой причине: полученная хеш-сумма должна иметь фиксированную длину. Т.е. если логически подумать то перебрав 2n комбинаций (где n — длина хеша в битах), мы стопроцентно найдем коллизию. Ну а если вы слышали про парадокс дней рождения, то для вас будет очевидным что достаточно будет перебрать «всего лишь» 2n/2 чтобы с достаточной вероятностью найти коллизию.
Конечно эти числа для хешей длинной более чем 100бит будут огромны. Например для md5 длинной 128 бит, полный перебор это всего лишь ~30 000 000 000 000 000 000 000 000 000 000 комбинаций, учитывая парадокс дней рождения надо будет перебрать совсем чуть-чуть, где-то ~18 000 000 000 000 000 000 комбинаций. На моем ноуте это «всего лишь» около 500 тысяч лет беспрерывного перебора.
Вродебы вот решение — используйте хеш функции с большой длинной выходной хеш-суммы. Но, как я говорил раньше, никто ни застрахован от того что ваш хеш от вашего пароля длинной минимум в 30 символов, не будет иметь коллизию длиной всего лишь в 1 байт. Пусть конечно эта вероятность фактически стремится к нулю, но она есть!
Стопроцентная защита от коллизий есть! Читайте под катом.
Решение проблемы
Вообщем что же делать? В данной статье я хочу попробывать предложить отказаться от хеш функций в пользу функций шифрования. Как вы поняли из заголовка, я предлагаю использовать ассиметричное шифрование. Почему именно ассиметричное?
Вспомним классическую (симметричную) систему шифрования. В ней данные шифруются и расшифровываются одним и тем же ключом. Теперь представте практическую реализацию хранения паролей с помощью симметричной системы. Помимо хранения паролей нам нужно будет хранить и ключ, но при этом если вдруг злоумышленник завладеет этим ключом, то вся безопасность системы рушится на корню, так как злоумышленник сможет без особого труда расшифровать все пароли. То есть нам нужна такая функция которая позволила бы только зашифровывать данные без возможности их обратно расшифровывать, а по факту — нужен аналог хеш функции только без фиксированной длины.
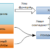
Теперь вернемся к ассиметричной. Ее прицнип заключается в том что данные зашифровываются одним ключем (публичный ключ) а расшифровываются уже другим (приватный ключ). Вообщем как то так:

Подробнее смотрите в этом моем посте: Ассиметричное шифрование. Как это работает?
А теперь представьте. Мы при генерации ключей удаляем приватный ключ, и храним только публичный. Расшифровать зашифрованные данные мы уже не сможем, злоумышленник тоже (даже если и завладеет публичным ключем), фактически получаем хеш функцию с переменной выходной длиной. На практике это будет выглядеть так: мы один раз генерируем ключи, приватный ключ удаляем, а публичный сохраняем где нибудь в конфиге, каждый пароль (не забываем про соль) шифруем с помощью хранимого публичного ключа и полученную строку (по сути — уже хеш) храним в БД:

При проверке авторизации, введенный пароль также шифруем хранимым публичным ключем и сравниваем со строкой в БД. Если строки идеинтичны то пользователь ввел верный пароль.
Собственно все =) На самом деле очень простая идея. Только проблема скорее всего будет в реализации на практике. Стоит ли защита от мизерной вероятности коллизии вашего пароля такого геммороя с ассиметричным шифрованием?
Итог
К сожалению такая система имеет огромное колличество минусов. И самый главный из них — это переменная длина зашифрованного пароля. Да и в реализации эта система довольно сложна. Не знаю будет ли кто нибудь ее применять, но как говорится неразрешимых проблем не бывает — проблему с коллизиями в классической системе хранения паролей мы решили =)



Интересная идея. Да и перебор такого пароля должен, по идее, занять больше времени(хотя, зависимо от алгоритма).
А в чём проблема реализации? В итоге все всё-равно сведётся к виду
crypt_pwd("password","path/to/public/key")Да и переменная длинна не такая уж и проблема если сам пароль ограничен например 30 символами, то у нас уже не будет шифрованных данных в over9000 символов, так что можно будет нормально использовать что-то вроде varchar(500). (500 — сферическое в вакууме число, зависит от того на сколько увеличиваются данные после шифрования.)
Проблема в том что практически ни в одном из скриптовых языков типа php, perl, asp и прочих, нет встроенных функций ассиметричного шифрования. Прийдется подключать дополнительные библиотеки, городить кучу кода для сведения всего к виду:
crypt_pwd("password","path/to/public/key")Да и насчет переменной дилины. Возникает проблема с размером БД и скоростью работы. К примеру есть очень огромная разница между хранить хеш md5 в виде CHAR(16) (именно 16, так как 32 байта он занимает в hex представлении) или хранить VARCHAR(500). Да, на простеньких сайтах с маленькой БД это роли не сыграет, но на крупных проектах это может тупо загнуть сервак.
Ну а вообще, я согласен, в целом идея неплоха.
Я погуглил с сразу нашел кучку готовых модулей, где всё примерно к такому виду и сводится. Так что тут проблемы как бы и нет.
Ну а про крупные проекты я не уверен, что переменный размер поля будет так уж сильно мешать. Разве что, если будут миллионы записей, но тут уже и подход к архитектуре другой должен быть.
Хм. Может быть вы таки и правы =)
Но согласитесь, есть разница, использовать обычную функцию md5() или подключать библиотеки, писать обертку под них и тд и тп. Может быть это не так весомо, но так или иначе это минус.
Ну а насчет переменной длины, я скорее имел ввиду проблему того что зашифрованный пароль может быть довольно длинной строкой. И грозит это увеличением общего объема БД.
Нет, вы не подумайте, мне нравится эта моя идея с ассиметричным шифрованием. Я всего лишь пытаюсь заранее предупредить о всех возможных недостатках этой системы =)
А теперь представьте. Мы при генерации ключей удаляем приватный ключ, и храним только публичный. Расшифровать зашифрованные данные мы уже не сможем, злоумышленник тоже (даже если и завладеет публичным ключем).
А злоумышленник, возьмет, да и воспользуется МЕТОДОМ БЕСКЛЮЧЕВОГО ЧТЕНИЯ.
Гм, вы о чем? Данный термин описывает всего лишь класс атак на шифры. И если уж, извините, выбранный вами алгоритм подвержен данной атаке — то вы сами себе виноваты.
Естественно при разработке данного алгоритма «хеширования» нужно выбрать наиболее стойкий шифр.
А если пользователь потерял пароль и хочет его восстановить? Ключа для расшифровки его пароля из БД нет. Как поступить в данной ситуации?
Происходит то же самое по аналогии с хешами, ему просто генерируется новый пароль. Старый естественно восстановить невозможно.
Ну, здесь я не соглашусь, что удобнее сразу генерировать пользователю новый пароль!
Это будет неудобно для пользователя, если он привык к своему паролю и ему придётся выполнять две итерации: генерацию и смену на свой в профиле.
Лучше сгенерировать линк с токеном на 1 час для ВВОДА НОВОГО ПАРОЛЯ самим пользователем и отправить его по почте (или PIN по SMS).
Как альтернатива: можно предоставить выбор после перехода по ссылке смены пароля: «ввести свой» или «сгенерировать случайный».
Конечно, не стоит допускать ввода последних N-вариантов или их производных: цифры, буквы, пунктуацию — эти символьные группы хранить отдельными хешами, чтобы можно было бы проверять по таблице предыдущих ПАРОЛЕСОДЕРЖАЩИХ хешей, которые хранят все символьные группы и общие парольные хеши (итого: 4 поля).
Не совсем укладывается в голове. А как сверить пароль пользовательский и хранимый в базе, не имея приватного ключа?
То есть, если мы зашифровали пароль с закрытым ключём и удалили его, то при сравнении паролей не имея закрытого ключа (так как мы его удалили), пароли просто не совпадут.
Шифруем не приватным а публичным ключом. Приватный ключ нам попросту не нужен, и отчасти даже опасен, поэтому мы его удаляем.
По шагам:
— в базе у нас хранится пароль пользователя зашифрованный публичным ключом.
— введенный пароль также шифруем публичным ключом
— сравниваем между собой, равны — пользователь ввел верный пароль
«Шифруем не приватным а публичным ключом»
Так это тот-же самый хеш. Только хеш*2. Суть не меняется … есть ключ по нему делается какая-то контрольная сумма, она и сравнивается.
Вся ваша схема сводится лишь к тому… что изменяется пользовательский пароль перед тем как сделать хеш… это как переставить буквы в пароле перед получением хеша, только перестановка чуть посложнее. Как была проблема одинаковых хешей так и остается.
Вопрос лишь в том, что быстрее перебрать — пароли или хеши…зависит от длины.
К сожалению, вы не уловили суть статьи совсем.
Проблема хеш функций — в их алгоритме «свертки» до строки фиксированной длины. Суть в том что из за этого могут возникать коллизии. Так например, вы используете какой то супер длинный пароль длиной в 50 символов. Существует вероятность того что хеш такого пароля будет равен хешу какого нибудь например пяти символьного пароля. Т.е. злоумышленник сможет авторизоваться в систему используя коллизию, а не искать полный оригинальный пароль.
Использование ассиметричного шифрования в данном случае — это не контрольная сумма в прямом ее понимании. Это зашифрованный пароль (далее «шифрохеш»), который можно расшифровать только приватным ключом, который мы целенаправленно «потеряли». Т.е. обратно пароль из такого импровизированного «шифрохеша» уже не получить.
Что это дает? У такого «шифрохеша» не бывает коллизий априори. Не могут два разных текста (в нашем случае пароля), зашифрованные одним и тем же ключом одним и тем же алгоритмом, давать одинаковые шифротексты. Появляется другая проблема — выходной «шифрохеш» получается произвольной длины, это нужно учитывать при их хранении в БД. И еще некоторые нюансы.
В предыдущей статье упомянули способ вычисления и проверки хешей разными алгоритмами. Он справляется с коллизиями, но плох тем, что один алгоритм будет заведомо хуже второго.
Можно использовать один алгоритм, но хешировать используя разные общие соли — один раз на одной, второй раз на другой. Тогда если коллизия произойдет с простым значением на одном варианте, то [почти] заведомо не пройдет на втором. Скажем, если и второе значение совпадет, то лучше сразу застрелиться…
Alex, шутка в том что два хеша разных алгоритмов, можно рассматривать как один хеш но всего лишь бОльшей длины.
Т.е. мы сделали
md5(string) + sha256(string)— в итоге мы получили 384битный хеш. Да, такой хеш более устойчив к коллизиям, но он по-прежнему уязвим, хоть, конечно, и на порядки меньше.Дмитрий, мне кажется Вы не до конца поняли.
Базово мы берем sha256 (createString(password, personalSalt, commonSalt)).
При этом у нас потенциальная проблема с тем, что возможна коллизия при подборе более простого пароля.
Я предлагаю брать хеш два раза используя разную соль, т.е. sha256 (createString(password, personalSalt, anotherCommonSalt)), хранить и проверять оба значения отдельно.
Тогда это не просто более длинный хеш, коллизия может произойти на одном из них, т.е. найдем другой пароль (anotherPassword), но хеш функция от него на второй соли даст принципиально другое значение, нежели мы храним у себя.
Даже в таком виде принципиальной разницы нет. Это не решает проблему нахождения коллизии в корне, так как рано или поздно найдется такой password который даст коллизию к двум хешам с разными солями.
Если абстрагироваться от солей и прочее, по сути опять получается хеш бОльшей длины, т.е. 512-битный. Повторюсь, чем длиннее хеш, тем он более устойчив к коллизиям, по вполне понятным причинам. Но сама проблема никуда не денется.
так в том то и дело, что это за password. По моему мнению это может быть только исходный, а не какой другой. Я говорю, что использовать два разных хеша от одного пароля совсем не то же самое, что в два (или в 10) раза больший хеш…
А значит устанавливая людоедские правила на сложность пароля для администраторов системы и выбирая адекватный времени алгоритм хэширования соответствующей сложности и устойчивости я могу контролировать уровень защищенности.
Все вышеперечисленное мне нужно для митигации риска получения админского уровня доступа за счет коллизии (одиночный хэш для очень сложного пароля оказался таким же, как и для простого)
Алекс, вы заблуждаетесь. У меня складывается ощущение что вы пытаетесь убедить в этом в первую очередь себя. Дело в целом ваше, но мне жаль что вы не хотите понять то что я пытаюсь до вас донести.
С точки зрения криптографии все эти извращения с разными солями, двумя хешами и т.п. — это лишь увеличение длины итогового хеша. Т.е. по сути это видоизменение алгоритма хеширования, которое не решает фундаментальной проблемы.
Рассматривать ситуацию можно с двух сторон:
— с практической — даже обычного одного sha256 хватит с головой чтобы исключить проблемы с колизиями для паролей в какой-нибудь админке какого-нибудь сайта.
— с теоретической — колизии неизбежны для любых хеш функций.
Но, к сожалению, это именно тоже самое.
А вот тут утверждать не буду, возможно. Я не на столько глубоко погружен в тему, готов поверить.
Если так, то жаль, мысль была интересная…
Поделить password на две части тоже никак не повлияет с точки зрения вероятности…? вроде не очень…
Поделить password на две части, и делать на каждую часть по хешу? Да, это уменьшит вероятность. Так же как и ваше извращение с разными солями) Но я бы все таки рекомендовал не заморачиваться с этим впринципе. Повторюсь, обычного sha256 хватит с головой для большинства систем.
Норм идея. Собственно мне она тоже приходила в голову.
И я думаю, скорее всего она уже применена 100 раз при хранении паролей.
Потому что про минусы с хешами паролей писали еще в конце 90ых в «поваренных книгах для кулхацкеров». (даже упоминались методики, которые генерируют «зеркальные пароли» у которых один хеш всего)